Background for the import can be found on the import’s OHM project wiki page, but I’m hoping some of the discussion related to the import here.
@Minh_Nguyen took a look at it today and provided some great feedback, improving the tagging, and asking some questions about methodology that will help with this process. I’m sure others may have some other perspectives or raise concerns that will be helpful.
I’m hoping to start uploading these relations on Tuesday, January 9th, so please let me know if that’s too too soon.
Also - I realize some of you may have already uploaded historical county relations & the plan is to not interfere with those, but I’d love to chat 1:1 with anyone if there are concerns.
First of all, I can’t stress enough how big of a deal this import will be for OHM in the U.S. I remember chatting with you and other OHM mappers a few years ago, before I got involved with the project, about how these boundaries would be critical for bringing in contributors. Well, I guess I proved myself wrong because I’m here already. Still, I think this will be for OHM what the TIGER import was for OSM – in a good way.
I have a few suggestions regarding the translation from the dataset’s attributes to OHM tags. None of them is necessarily a blocker, but I think we’d want to avoid having to revise all the boundaries multiple times in response to systemic feedback, if we can help it. Eventually it will become more difficult to make those revisions, as mappers manually fix factual errata from the imported data. For example, I hope to redraw all the Ohio counties along Lake Erie to include the lake, which the Newberry dataset intentionally ignores.
The Newberry dataset’s CHANGE field has been translated to start_date:cause. I think this would be a good opportunity to migrate to start_event. The current popularity of start_date:cause doesn’t even matter given the sheer scale of this import.
source:cite strikes me as odd considering the conversation we’re having about source tagging. I agree that we should include the original citation, but could we make that a source:2 instead?
Along the same lines, I’d encourage you to establish a newberry_ahcb:* namespace for anything dataset-specific that you want to “carry along” in OHM, rather than coining single-use keys under source:* that may conflict with unrelated citations in the future. This is a good practice in general that avoids the need for linguistic gymnastics and mitigates the risk of skunking a tag.
The license=CC0 / public domain tag is fine for now (modulo the unresolved issue of how to spell the key), but I’d encourage us to consider supplementing these human-readable strings with a machine-readable SPDX license identifier to facilitate safe reuse of OHM data.
I appreciate the note about creating chronology relations out of these boundaries. Once they’re created, we should add OpenHistoricalMap relation ID (P8424) statements to the corresponding Wikidata items. Conversely, the wikipedia and wikidata tags should be moved from the individual boundary relations to the higher-order chronology relations.
Do I understand correctly that there’s only one place node per county, even if the county’s centroid has shifted over time due to changing boundaries? This will result in some very unexpected labeling in some cases. For example, Hamilton County’s averaged centroid wound up in present-day Montgomery County, two counties to the north. Similarly, Knox County, Indiana, is all the way over in Putnam County. This will tend to affect any of a state’s original counties, from which smaller counties were carved out.
I’m glad I didn’t have to deal with this issue in the San José boundary import, since the place node for that city could be located at a fixed spot with real significance rather than an arbitrary centroid. We did end up with multiple place nodes due to name changes, though not one for each iteration of the boundary. I don’t have a good short-term solution for the county place nodes. We should prioritize synthesizing centroids automatically when generating tiles and deprecate and delete these manual centroids as soon as possible after the import. (Needless to say, I find the label and label_id keys to be superfluous.)
Just as the place nodes’ name tags omit the years, I think the boundary relations’ name tags should also omit the years. Software should be able to append the dates when appropriate, according to the user’s preferred date format (which is not necessarily equivalent to the English format, even for a CE year range). I realize this will cause some temporary inconvenience when perusing Nominatim results, but conversely, the current tagging results in clutter in iD. Given the time it would take to deploy a fix to ohm-website’s Nominatim integration code, this could be a followup edit.
Finally, what’s the vintage of the newest data in the Newberry dataset? My understanding is that the dataset is no longer actively maintained as far as present-day changes, but there have been a handful of significant changes in recent years, such as the renaming of Shannon County to Oglala Lakota County in 2015. If we know the dataset’s vintage, that’ll make it easier for us to coordinate a more manual update of the counties up to the present.
And, second of all, thank you! for this detailed feedback.
Barring any objections, let’s do it. I’m hoping to update the historical state boundary relations, so we can fix those too.
Totally agree… it’s been bugging me a bit, too. Any thoughts on whether source:2 might imply that the mapper actually found the source, as it’s really info that has been provided by source:1? That said, source:2 might provide an easier method for updating or showing alternate information that conflicts with Newberry’s research.
We could certainly do this. My original intent was to create some sort of system that might be used across various sources, particularly for common fields like “ID”. A particular example of this is for labels that are marked in the legend of a map - e.g. “a) Ye Olde Candee Shoppe” (usually just “Candee Shoppe” when it was new…). And, the goal was to avoid a proliferation of source-specific keys. But… certainly not a problem! Should we add a something like import=newberry_ahcb?
I’m a huge fan of the , but in this case, let’s avoid them. !!
What about both? When reuse is a question, it’s nice to not require an indirect lookup.
That is the plan!
[And… perhaps off OT here… the next comment has me wondering if there should be another Wikidata identifier for geodata or a territorial evolution and should we have a pointer to an OHM endpoint that provides a non-OSM format (e.g. GEOJSON) of download for the chronology shapes? ]
Can you explain more? I thought we wanted the wiki tags whereever there was an instance of an entity. Without additional work, this would prevent the inspector from providing information about the individual relations from showing up on the inspector. Understood that this functionality may or may not be problematic, but we do have it now.
This is correct & while I had originally thought it would be “good enough” and that we could handle exceptions on a case-by-case basis, knowing that some wouldn’t work (see: Summit County chronology relation).
It shouldn’t be too hard to redo these label points and create additional points for centroids that are too far off of the selected labels. Or, I could just create 17K label points instead of 4K. Across the entire US, the point density would be pretty small in general.
Agreed & nothing stops anyone from moving these label points as appropriate or best suited for the locale. IMO, it should be encouraged… moveme=hell yes?
Is it a foregone conclusion that automated label placement is a better solution than manually-created ones? I need to find a link, but I remember a presentation from Kelso (I think?) on automated label placement that left quite an impression on me of the problems with label positioning conflict. Agreed that 'label` is sort of odd, but the intent is to clearly identify that it’s an explicit label for a relation, which may not be obvious if someone isn’t looking closely.
Let’s do this and I’ll follow up with some tickets. Agreed that it would be very helpful functionality across the board. Given iD is working, obvious candidates for fixes include Nominatim, JOSM… anything else?
As noted in the import plan, the oldest date is end_date=2000-12-31, so anything after that - Ogala Lakota, some Alaska borough changes, and others I am sure, will need to be added. I’m looking forward to having an up-to-date, error-corrected dataset available in the future… end of the year?
Maybe others can chime in on what’s considered good practice when citing a tertiary source. I haven’t encountered this situation very often because I usually work with secondary or even primary sources. My impression is that it’s OK to cite them both as ordinary sources. We’re still listing the Atlas first, after all.
Another option would be to treat the Atlas as not a source unto itself but rather a method for accessing that source. Most style guides have provisions for citing the database you access, for example, ProQuest or NewsBank. Wikipedia’s citation style presents these as “(via …)” at the end of the citation, using the |via= parameter. But if the Atlas involves much more than aggregation, then it should be a source in its own right, not just an access method.
What we do here probably has implications for how we want others to cite OHM: do they also cite our sources as their own? Do they cite us as a source or just a means of access? Anyhow, my gut reaction was just that source:cite is a funny key because it’s basically just saying source:source using a synonym.
I don’t think the IDs can be used out of context anyways, since they aren’t part of a larger standardized system of pinpoints, as you might find in some legal databases. As long as the keys are namespaced by something reasonably unambiguous, proliferation is not a problem at all. OSM has used import in the past, but I would omit it; it’s nothing more than a kind of source key and would get confusing the moment we need to modify any of this data in a subsequent import of a different source.
If you’re concerned about discoverability, you should document the keys on the wiki and also create a taginfo project file for the import:
The SPDX identifiers are already nearly human-readable. They’re basically just standardized spellings of abbreviations people use every day, plus version numbers (which we should be using more rigorously). If not for the existing widespread usage of license=CC0 / public domain (probably by other imports), I’d recommend just tagging license=CC0-1.0. Editors and data consumers would be able to expand this ID to the full license name as space allows, and also localize the name.
The most important thing is to have these tags on the chronology relation, to reciprocate the statements on Wikidata that link to the chronology relations. Wikidata refuses to link to individual boundary relations because it doesn’t scale well.
The presence of wiki tags on the individual boundary relations isn’t necessarily an immediate problem, but it greatly complicates anything that someone would do with OHM boundaries in a federated query with Wikidata. It will also be a maintenance burden to keep the wiki tags in sync between the chronology relation and its members. We keep discovering that Wikipedia has intentionally conflated boundaries with other things, requiring us to refactor the Wikidata items away from that state of affairs. (Fortunately, this isn’t as much of a problem with counties as it is with more local subdivisions, like a township, historic district, island, and wildlife management area all rolled into one. )
The code to fetch the Wikipedia snippet from the element is not that complicated and can easily be modified to go one level up to a chronology relation. Once that happens, I think we should remove the redundant tags from the members.
I’d just leave them as is for now, so that they motivate us to fix the problem by deleting these place nodes in favor of something in the tile generator.
You’ve already proven that it’s feasible to create centroids out of boundaries automatically. Automatic label placement is not perfect in terms of avoiding label collision and such, but these automatically generated, manually stored centroids can’t solve those problems. Long-term, place points should ideally be reserved for places that we don’t know the boundary of, or for which the point representation in a particular place holds some additional semantic value that can’t be derived from the boundary (such as the San José nodes, located at the origin of the street grid). The locations of these points only matter presentationally; semantically; they’re purely source=arbitrary.
The website’s browse pages are the main area for improvement, and I think it might also address Nominatim to some extent:
JOSM is already capable of what iD does, but you have to specify a name template for each preset you want displayed differently. Maybe they could be persuaded to implement a universal default or add a hook for a plugin to do it. It doesn’t sound terribly complicated technically.
OK, that’s recent enough that we should be able diff the Census Bureau’s TIGER and BAS shapefiles to detect changes and patch up the Newberry boundaries accordingly.
What happens when there is only an individual boundary relation and no chronology relation? E.g., Delaware, New Jersey, and South Carolina have their original boundaries to this day (as states).
Or, when a member of a chronology relation and the chronology relation have different Wikidata codes? Or, a user wants to create a chronology that doesn’t exist in Wikidata? Or, the Wikidata structure / data model doesn’t appear to support an entity someone might want to have as part of a chronology relation? (I think the answer is “please fix Wikidata,” which I’d love to have people do, but I’d hate to burden that as a hard requirement.) E.g., I don’t believe there’s a Wikidata entity or Wikipedia article for the US Colony of Virginia, but I could be wrong (there’s a British Virginia Colony & US State article). Luckily, there’s no Confederate State of Virginia article or entry, but that was a thing and it wasn’t a US State…
I love the idea of alignment and cross-linking whereever possible - wouldn’t it be simpler to encourage one-way linking everywhere and letting machines manage two-way linking and ignore redundant / unnecessary tags as the Wikidata models get fleshed out? (The alternative approach being to teach users more complex rules - e.g., add Wikidata codes here, but not here, etc.)
In this case, the Wikidata item links directly to the boundary using the same property. What Wikidata doesn’t want to do is store a time series of the boundary data directly inside an item. They want OHM to store the time series, because our data model can do it more flexibly.
Yes, the most important link is from the OHM chronology relation to the Wikidata item. The link in the other direction is for convenience – specifically, to facilitate federated queries – but it isn’t essential. I don’t mean that you should hold up this import to figure out what needs to be edited on Wikidata. The wiki tags on individual members of these relations is problematic because they imply that the territorial evolution is the same concept as the territory itself. But it isn’t the only thing that currently frustrates attempts at using linked data. If you need to link from the individual boundaries to the Wikipedia article or Wikidata item for now, that’s fine, but don’t expect that to be the case in the long term.
These are great points I’ll put on the source=* wiki page (soon : ) ).
A couple ideas I had this morning:
Tagging a source’s source is probably not best practice, for the reasons discussed above: we don’t want to create appended lists of sources that drag behind every node in a dataset.
If there were some compelling reason to include a source’s source - e.g., some sort of really juicy tidbit that we were sure all OHM’ers would be dying to know with 100% certainty (i.e., almost never), we should do it in a way that acknowledges the source’s license scheme. In this case, AHCB is CC0, so, no requirements, so use source:2=*. If there were some form of attribution requirement, we may want to consider adding an import-specific tag: e.g., newberry_ahcb:source=*.
In this case, unless there are objections, I’m going to omit the source:cite / source:2 tags for this import.
Alrighty community, I need your help & guidance about how to handle some spatial issues with the proposed Newberry Atlas import.
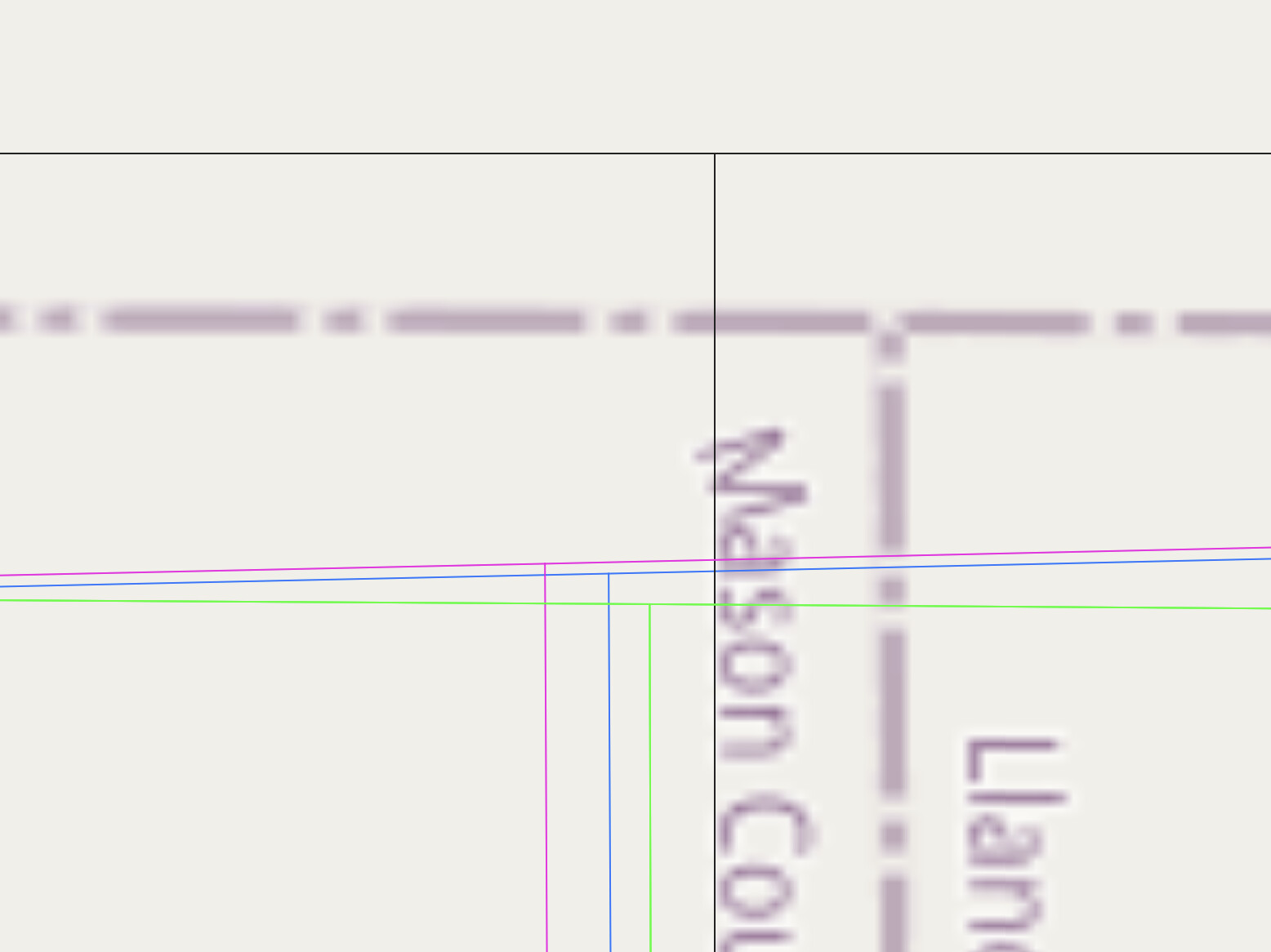
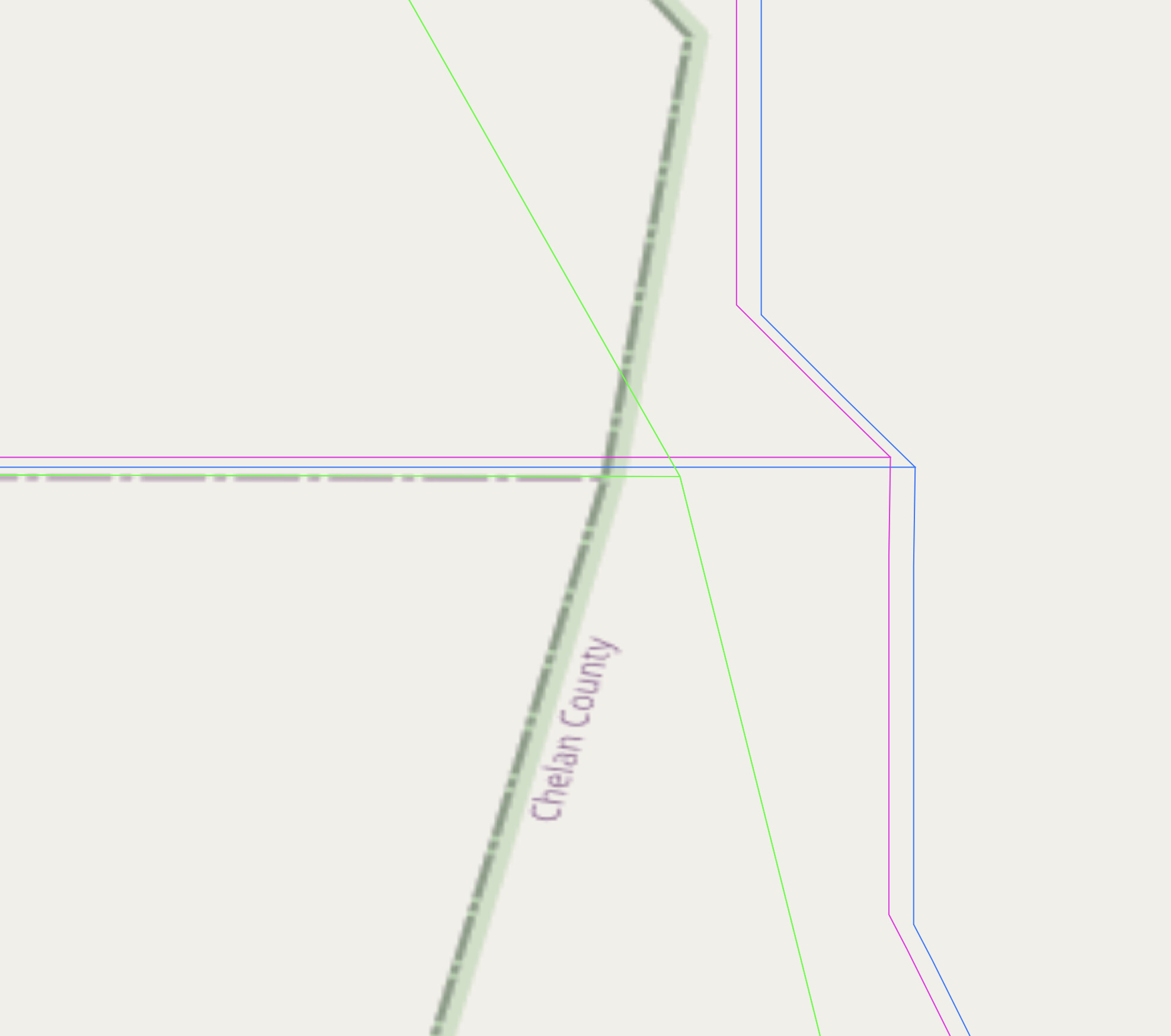
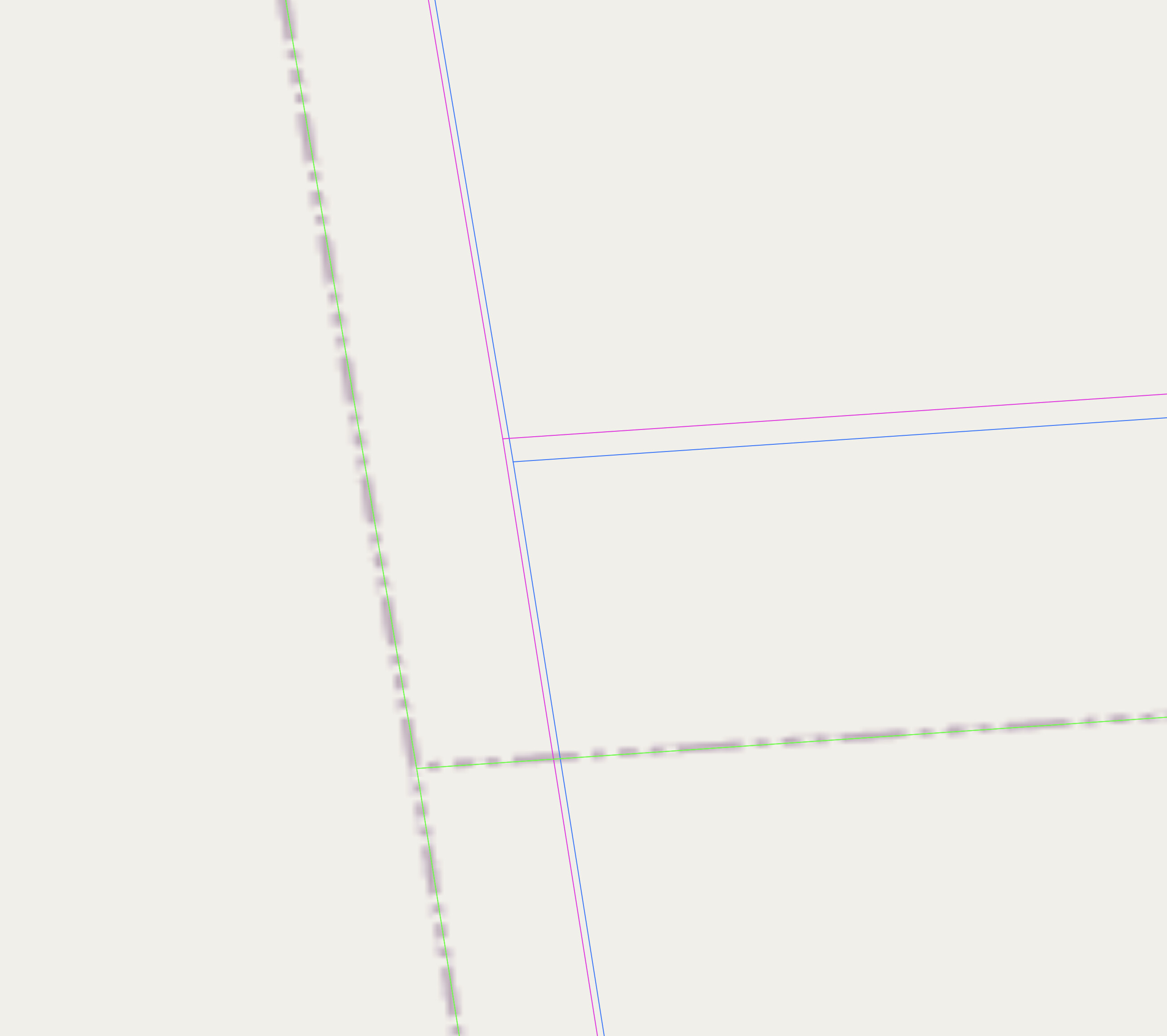
After much wrestling with transformations, etc., over the past few days, and trying to address issues related to the spatial accuracy of the source data, along with a questionable transform, I am at a bit of an impasse, as shown by the 4 sets of boundaries shown in the image below:
The blue line (the southernmost intersection) is the source data as already imported into OHM.
The pink line is a corrected NAD83 → WGS84 transform of the source data (blue lines) using the steps outlined on the OSM wiki.
The green line is the from the 2018 county dataset at the US Census.
The thicker, dashed lines on the base map are from OpenStreetMap.
And, the dark, northernmost lines are from the Texas DOT Geoportal, dated 2022.
(I would have labeled this image better, but Parallels - installed to use QGIS on Windows for the transformations - appears to be screwing with my screenshot software…)
Without regard to which is “correct,” the distance from the westernmost to the easternmost intersection is about 8m and the distance from the southernmost to the northernmost intersection is about 11m.
The 3 clustered sets of lines are about 2m across and 1m up and down. The pink lines, which are supposed to be the corrected version of the lighter gray lines. I am sure these relative positions might change for different counties in different parts of the US.
So, here’s my question to the community:what should we do with the data, as prepared and already uploaded (Blue line)? Go ahead and keep it for now, knowing that it’s off by 10-20m in some cases (MA) and wait for local mappers to improve these alignments? Upload the similarly-off, but “better” transformed data (pink)? (this would seem odd to me!) Wait to upload the county histories until they are all aligned with each state’s current boundaries? There are pros and cons to each approach, but I’d love to hear what the community has to say (and I’m praying someone has a great answer).
[On a separate note, it turns out that conducting a proper NAD83 → WGS84 transformation for Canada, as required for Oregon Country, is much trickier (1, 2) than the well-trod path laid out for US regions…]
My measly two cents, as someone who maps all things crudely by hand without much regard for actual coordinates, is that the import has significant value even if it’s offset by a significant amount, as long as users can infer the intended boundaries. I think this is a more reasonable stance to take for a medium-scale feature such as a county line than for an individual property line.
I don’t think we should worry about aligning the historic boundary data to current boundary data just yet. For one thing, none of the national sources of boundary data addresses the issues you’ve raised here. Some states have much better sources that are unencumbered by copyright, making them preferable to anything we’d import from OpenStreetMap. Having redrawn some of OSM’s county boundaries myself, I don’t have much confidence in OSM as an authoritative source for not only modern boundaries but also historical boundaries that happen to resemble the modern ones.
To put things into perspective, I anticipate that we’ll need to correct some major factual issues once the import is complete, such as:
Extend state and county boundaries from the lakeshores of the Great Lakes to the international boundary with Canada – a distance of tens of miles.
Refine state and county boundaries along the Ohio River to reflect the dispute among these states that lasted from statehood until the 1990s – not a large distance, but a significant one that involves a number of islands and part of a major city.
Adjust the tags on some of the counties of Indian Territory and Oklahoma Territory to reflect tribal administration.
Refine national, state, and county boundaries along the Rio Grande according to various treaties and rulings, as islands appear, disappear, and get transferred from one country to the other.
Whether you leave the already uploaded geometries alone or replace them with reprojected geometries depends on how tedious it would be to replace the geometries. Once the boundaries and relations are all uploaded, we can expect mappers to start splitting some of the ways and adding more relations to each chronology as we gain detail both geographically and chronologically. I’d imagine this would frustrate any attempt to replace the geometries en masse. But I don’t have a good grasp on the process for converting this data into OSM’s data model.
To be clear - I am not suggesting we import anything from OSM & specifically am stating that we will not import any county-related info from OSM. I only included it as a point of reference, in case anyone was hoping to use OSM as a standard for comparison.
Just to put it out there to begin with, most of the county lines in OSM are objectively terrible… the source dataset was only intended for 1:100,000 scale mapping (large scale topo maps) and includes many random meanders when viewed at the scale we work on. I’ve made a start at using the historical references in this dataset, and the BLM PLSS corners, to fix county lines in Alabama, and they are often a good hundred feet off.
The real issue is, how “accurate” are the lines in this dataset, as opposed to how precise. They are clearly more precise than the TIGER lines… they show meanders that are missing from that data. If the actual accuracy is to a level better than what is added by the transformation, then it would seem worth doing the new upload… OTOH, if they are themselves offset by more than the 1-2 meters corrected by the transformation, then it would seem somewhat pointless.
It’s hard to really know the answer without comparing them to lines based on the PLSS corners (which are presumably the best data we can find). Comparing portions of the first county I updated to with PLSS (Autauga County, Alabama) it seems like the Newberry lines vary from “right on” to about 30 feet off… so, drastically better than the TIGER data. At the same time, it does seem like the general “direction” of the coordinate transforms (northwest) would bring the lines closer to the ones I drew from PLSS.
I think it really comes down to a judgement call… do you feel like it’s worth the effort?
Plus, in most cases, changes to a boundary over time would be more interesting than the precise contour of that boundary at a point in time, at least until we’re able to build up OHM to an OSM-esque level of detail. @jeffmeyer, do you have a sense of the distance spanned by a typical county boundary change, or perhaps the average area gain/loss in a change that doesn’t involve splitting or merging counties?
I’ve gone though the history (from the sources in this) for three different Alabama Counties so far (Autauga, Baldwin, and Barbour).
In the first two cases, even the “reshuffling” changes were fairly dramatic, either from one township/range line to another, or (in the case of Baldwin) moving between river branches in the Mobile River delta… these were moves on the scale of miles.
For Barbour County the same thing was generally true (one move was ~40 square miles), although there several smaller changes “to accommodate a local landowner”.
That’s really not a good sample set, but I haven’t seen “nitpicky” changes that wouldn’t be apparent on even a large scale topo map. The smaller ones were:
“to include one hundred and seventy acres in section thirty-four, township thirteen, range twenty-nine, now part and parcel of the estate of Jesse Lee, of Barbour county, within the boundaries of Barbour county”
“to include sixty acres in section nine, and ninety acres in the southeast corner of section eight, in township thirteen, range twenty-eight, now part and parcel of the estate of Americus C. Mitchell, of Russell county, within the boundaries of Russell county”
to include “the south-east quarter of section eighteen, in township twelve, and range twenty-six, and sixteen acres on the south side of the northeast quarter of section eighteen, in township twelve, of range twenty-six, now part and parcel of the real estate of W. M. Russell of Barbour county, within the boundary of Barbour county”
These all moved the line (over some distance) about a half mile.
For comparison, my current record for how far a TIGER corner was just “wrong” was ~610 feet.
For county equivalents, the centroid points have novel primary tags such as place=parish and place=non-county area. I think these values may be too granular. If these are all county-equivalents, then they should be tagged place=county. We can use some other tag to capture the locally understood terminology in the local language.
Since place=* is a key that renderers and geocoders use to make generalizations about places, it needs to be machine-readable, even at the expense of some semantic precision. None of the conventional place=* values in OSM completely aligns with the literal word in English in any jurisdiction. This is by design, so that data consumers don’t have to reinvent the wheel for every jurisdiction.
“County” has various meanings across geographies and time periods, but I think the various meanings are close enough from a data consumer’s standpoint that aligning with OSM’s definition won’t be much of a problem in practice. No software will assume a place=county is the domain of a count, nor will it assume that a place=county is headed by an elected county judge.
By contrast, place=parish is problematic because it risks confusion with parish=*, for religious institutions and boundaries. This import facilitates mapping of various denominations’ diocesan boundaries, which may enable us to map parish boundaries in some places. Civil parishes should be distinguished because it’s the more figurative application of the word “parish”, used in fewer parts of the world and only more recently.
I don’t think this issue is a blocker for the import, since I anticipate that the tile generator will soon generate these centroids for us automatically, allowing us to delete them in favor of the boundary relations’ tags. The boundary relations have the advantage that we can already differentiate between, say, administrative and religious_administration boundaries.
Congratuations! It looks like all the boundary relations have finally been imported (and reimported after a mixup between start_date and start_event). What’s left to do for this import? It would be really nice to have those chronology relations in place so we can remove the parenthetical from each boundary relation’s name and link each county’s Wikidata item to an OHM relation that represents the county overall.
I wanted to come back to this point, in case it’s been a source of hesitation:
I’ve created many chronology relations about things for which Wikidata lacks an item, let alone an “evolution of” item. But every extant county and most former counties already have items, so we should try to link them up where possible. It’s perfectly fine to link a “Springfield County” item to a chronology relation without creating a “territorial evolution of Springfield County” item, but you can do that too if you want.
OpenRefine makes it very easy to add statements to Wikidata’s county items that link to the corresponding chronology relations. All you need to do is come up with a CSV of relation IDs, names, and states, and maybe some dates, and then you can use the point-and-click interface to match the relations to items in bulk. If you’ve already performed this conflation and just need to go in the other direction, OpenRefine supports uploading the edits directly to Wikidata.
Correctly tagging the chronology relation and Wikidata item will enable users to craft federated queries about questions that are otherwise difficult to answer. Some queries are possible with the current modeling of wikidata tags on individual unrelated boundary relations, but it requires some gymnastics that are more difficult and less performant.
Ha! Have no fear… there’s plenty of work left to do - I was briefly distracted with some prep for meetings this week, but here’s what I see as remaining:
create chronology relations for counties
fix labels
publish OHM county chronology relation IDs in Wikidata
At this point, the counties will be done & I hope to finish over the next 2 weeks.
After that, I still need to:
Repeat this process for the states boundaries, which should be expedited by lessons learned in the county boundary import.
Create country boundaries for the United States over time, chronology relation, etc.
Then, remove the old, very long & unbroken segments used in the original import.
And, then… there are a few more US admin-level 2 & 4 type things related to the Civil War, but we’ll see.
Oh, I was under the impression that the state boundaries were already fully imported. I was about ready to start redrawing some state and county boundaries along Lake Erie that the Newberry dataset got wrong. Should I hold off until you’re done with reimporting these boundaries?