a thing we periodically discuss without necessarily making a lot of progress is the challenge of finding mapped stuff in OHM. the wiki kind of helps, but no one is required to update the wiki or even use it, and there’s nothing on the website that even hints at the projects stuff on the wiki.
obviously we should fix that, but then, there’s more we can do. i’ve spent much of the last year with OpenSearch in my head, and OpenSearch is something we can use.
so my notion is to devise an OpenSearch schema that includes links to relevant items in Wikidata/Wikipedia/Wikimedia Commons (when known), and to the corresponding OHM entities.
i’ve been thinking about it pretty hard and i see no technical objections. there are potential licensing issues (which is one reason why this proposal does not include OSM entities at present.)
looking for comments and concerns.
the project needs a name. suggestions welcome
i talked to Quincy Morgan briefly about available resources for hosting an OpenSearch instance. we’ll be working on it.
right now i’m still pondering the architecture of the search documents. OpenSearch (and its predecessor, Elastic Search) are built around indexes containing search documents; these documents are what are returned in response to a search query.
we will need to be specific in stating what things are indexed. this will likely be relations of specific types, or nodes or ways that are not included in something higher level but meet other criteria. the criteria will need to be what tags are present, which minimally will need to be a name and a tag indicating what it is. we probably only want to include things with identifiable start_date or end_date tags.
the documents contain the various items that the search query can interrogate, and ids; the ids are for finding the entities outside of opensearch. they will be relation/way/node ids, wikidata items, names of wikipedia pages, etc., whatever we are referencing.
the searchable data will be from OHM, possibly beefed up from wikimedia commons where links exist. we should not include OSM data out of an abundance of caution with respect to license considerations.
@nfgusedautoparts - this would be great!
Do you have any draft search documents for others to review?
i have the beginnings of a document schema. it is set up as a template which can be applied to any index with a name that fits a pattern. i think the preformatted text may fail here when i post; we shall see.
{ "index_patterns": [ "ohm-index-*"], "template": { "settings": { "number_of_shards": 2, "number_of_replicas": 1, "analysis": { "analyzer": { "default_search": { "type": "standard" }, "keyword_analyzer": { "filter": ["lowercase", "english_poss_stemmer"], "tokenizer": "standard" }, "edge_ngram_analyzer": { "tokenizer": "standard", "type": "custom", "filter": [ "lowercase", "edge_ngram_filter", "english_poss_stemmer" ] } }, "filter": { "english_poss_stemmer": { "type": "stemmer", "name": "possessive_english" }, "edge_ngram_filter": { "type": "edge_ngram", "min_gram": 2, "max_gram": 25, "token_chars": [ "letter", "digit" ] } } } }, "mappings": { "dynamic": "strict", "properties": { "ohm_relation_id" : { // SQL BIGINT "type": "long", }, "ohm_way_id": { // SQL BIGINT "type": "long", }, "ohm_node_id": { // SQL BIGINT "type": "long", }, "wikidata-item" : { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "wikipedia-name" : { // same format as OSM Wikipedia tag "type": "text" }, "name" : { // OHM tag "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "description" : { // OHM tag "type": "text", "analyzer" : "edge_ngram_analyzer", "search_analyzer" : "keyword" }, "note" : { // OHM tag "type": "text", "analyzer" : "edge_ngram_analyzer", "search_analyzer" : "keyword" }, "start_date" : { // need OpenSearch EDTF but unlikely to get it "type": date }, "end_date" : { "type": date }, "other-ohm-tags": { // these should be key/value pairs "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } } }
yes, that did not end well. will put it on a web page and link to it.
this is better, but clearly i need to switch from emacs to an actual json editor.
improved but there’s still one slightly non obvious json glitch. and i had to remove my comments because of course json doesn’t permit comments. foo.
note that presently i allow for OHM relations, ways and nodes, and wikidata items and wikipedia article names. this should be expanded to cover OSM items we may wish to refer to, and other data sources as we identify them.
operationally, we can always decide to add more fields to the document, but that may entail a need to rebuild the index. this could be time consuming, but there are ways to avoid an actual outage when that happens.
we will need to consider what kind of spider is needed to crawl the data sources and figure out what is acceptable to the owners of the data sources being crawled.
there are currently no geo elements in this document. OpenSearch certainly handles geo searches and we need to consider how we represent this in the schema. it will need to be derivable from what we can get from the databases we crawl (OHM, Wikidata, Wikipedia, etc.,)
OHM data from tags is a bit sparse; this search will be most valuable when OHM entities are associated via wikidata/wikipedia/other links so we have stuff to search for.
using progressively higher level relations to group related things is a loser; the API limitations alone are enough to kill it, but the complexity of creating and maintaining such relations in our current editor choices is also unacceptably high. some sort of approach to tagging to indicate “hey these things are related” might be in order. the word tag itself it already has a specific meaning in the OSM schema, so we probably don’t want to use it directly, but the idea is there is a key in OHM that might have multiple comma separated values indicating associations, e.g. #Battle_Of_First_Manassas,#Battle_Of_Second_Manassas
doing this sort of labeling would facilitate search hitting on relevant entries. so the temporary burials i’ve mapped for Antietam would get Antietam labels because they’re associated with the battle, and a search for Antietam Cemetery would pull them up.
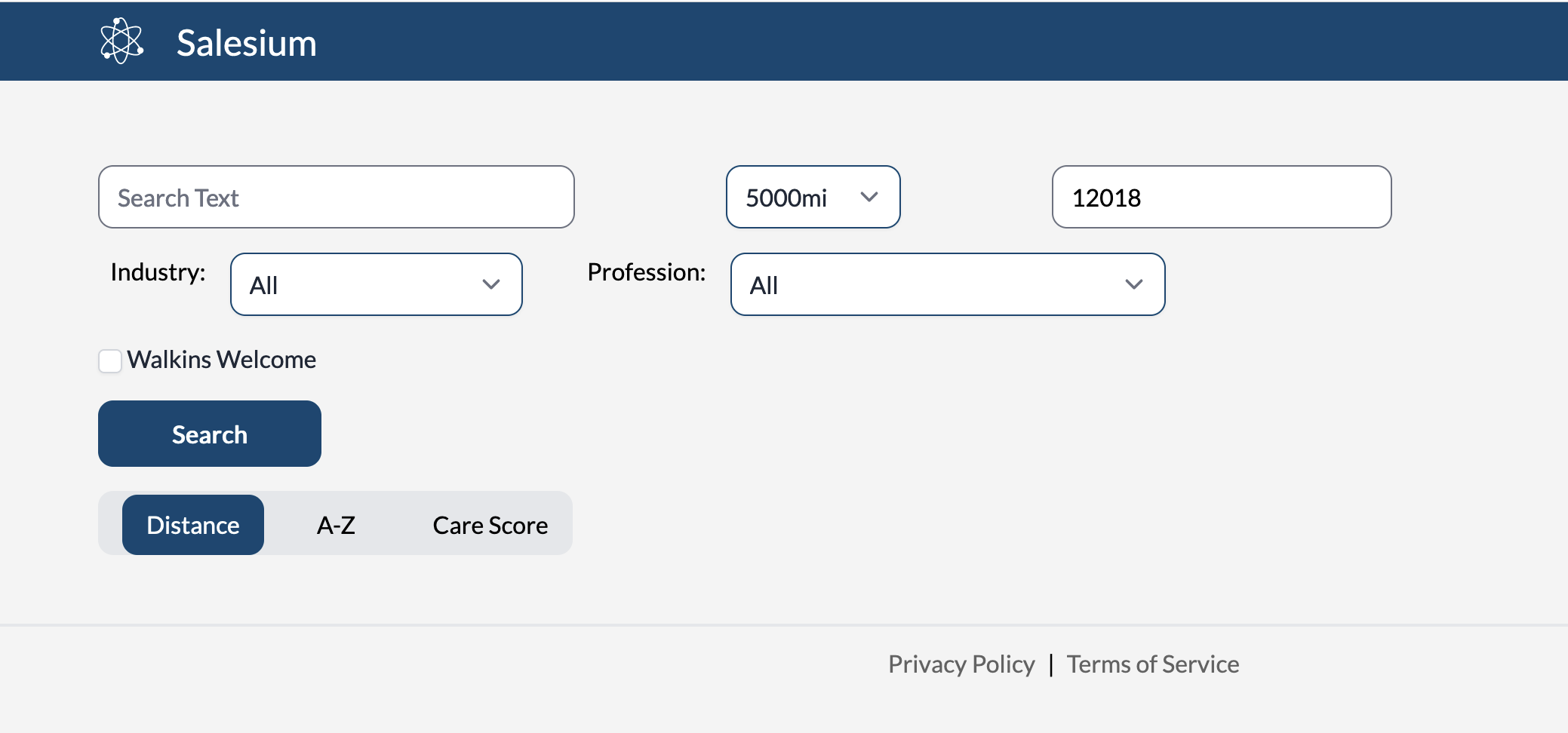
there are two ways to approach the UI; the old fashioned single text box (the old google “i’m feeling luck” and an advanced search page. the attached screenshot is of the advanced search page i setup at my startup, just to throw out some ideas
considering the crawler, i’ve been thinking about how it can handle geo boundaries, and how we might group things. the OSM site relation proposal is moribund. but using boundary=place might just work. look at the OSM wiki page and tell me what you think.
the boundary polygons map directly to OpenSearch planar polygons for search purposes, and the place=nodes can map directly to OpenSearch geopoints.
i put in a place boundary for Disneyland ca. 1960 using this model. when OHM Nominatum updates i’ll poke it with a stick. i used place=theme_park (tag info didn’t show any suitable place= values in OSM.)
Does it need to live within the place=* tagging scheme to be searchable? The standard tag in OSM would be tourism=theme_park. It’s mapped as an area or sometimes a multipolygon relation. OHM’s tile generator doesn’t recognize this tag, so it doesn’t render yet, but for example Nominatim has built-in support for it.
i don’t know that it needs to. i can try the tourism tagging. place tagging works decently if not perfectly with Nominatum, theme park might be a little cleaner.